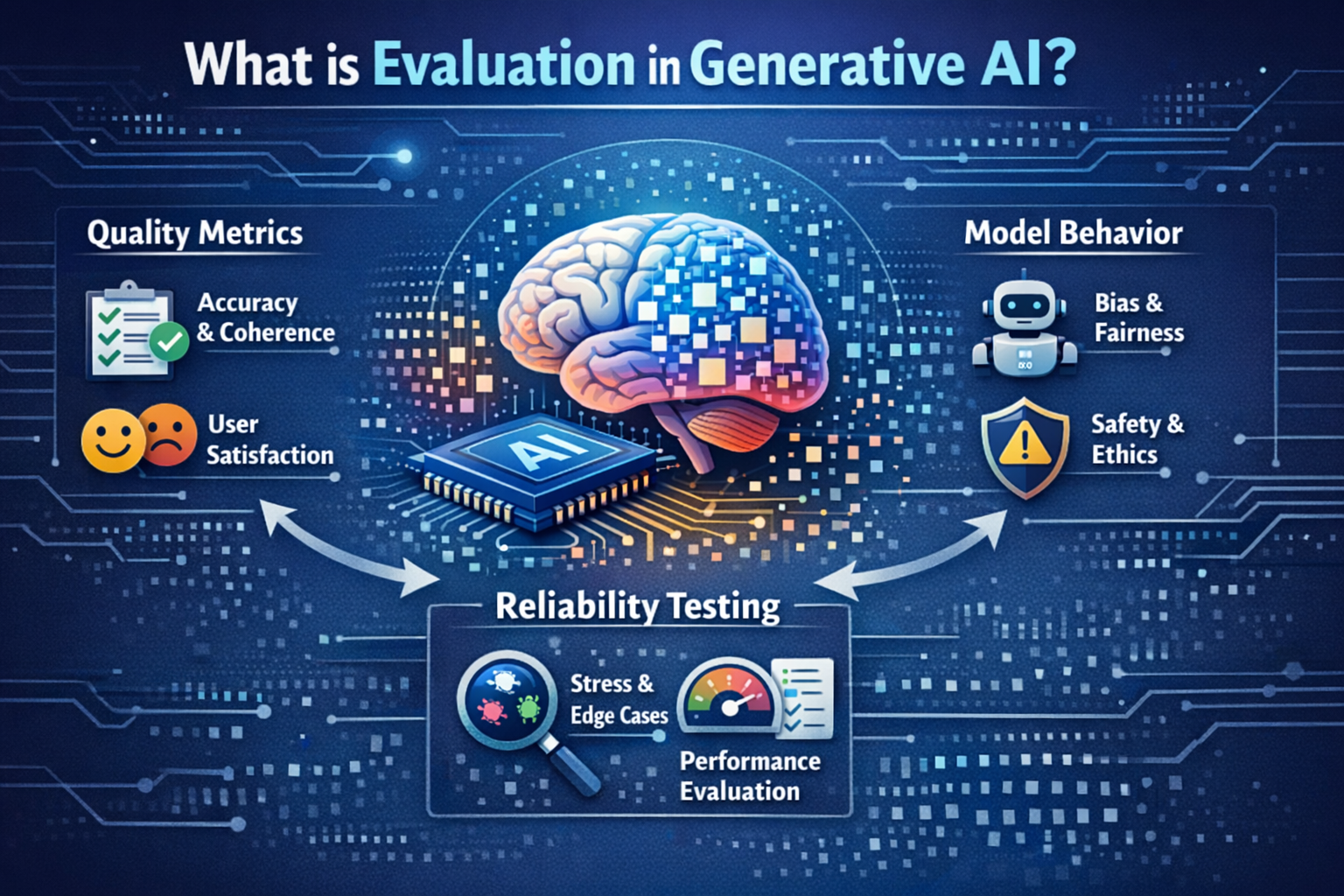
Generative AI is now being used to create text, images, and even business content, while these models can produce impressive results. This has made the evaluation of their quality of paramount importance as building them. A model that looks good on the surface may still produce incorrect, biased, or inconsistent outputs. That is why evaluation plays a key role in real world AI use.
Learners who begin their journey through a Generative AI Course in Delhi are introduced to this idea early. They understand that generative models must be tested carefully before being used in live systems. Evaluation helps teams decide whether a model is ready for deployment or needs improvement.
Why Evaluation Is Important in Generative AI?
Generative AI does not follow fixed rules, it learns patterns from data producing responses based on probabilities. Because of this, two outputs for the same input can be different. Sometimes the response is accurate and useful. At other times, it may sound confident but still be incorrect.
Evaluation is beneficial in answering basic questions regarding model production or stays on topic. Without proper checks, it is a risky game for the company spreading incorrect information.
Understanding Output Quality
Quality in generative AI is not just about grammar or presentation, it also includes relevance, and usefulness. A high quality response should match the intent of the user providing helpful information.
In a Generative AI Course in Noida, learners practice reviewing outputs from language models. They check whether the responses answer the question clearly and whether the tone fits the expected use case. For example, content written for customer support must be simple, while technical explanations must be precise.
Students also learn that quality depends on context, a model trained for creative writing will behave differently. An Evaluation must always consider the purpose of the model.
Common Quality Metrics Used
Several metrics help teams measure how well a generative model performs. Some are automated, while others rely on human judgment.
Relevance checks whether the output matches the input request. Fluency checks whether the response reads naturally. Accuracy focuses on factual correctness. Consistency looks at whether similar inputs produce stable results. Safety checks ensure the output does not include harmful or inappropriate content.
Learners understand that no single metric is enough. A combination of checks gives a clearer picture of model quality.
Studying Model Behavior Over Time
Model behavior refers to how a generative AI system responds across different situations. Some models behave well during testing but show are always the opposite patterns after deployment.
Through training in a Generative AI Course in Bangalore, you will get to explore how model behavior can change everything. They also learn that behavior can change as data patterns shift, or on older data may not reflect current trends.
Handling Bias and Unwanted Patterns
Bias is a common problem in generating issues, if the training data reflects unfair patterns, the model may repeat them. This can affect content tone, or responses related to sensitive topics.
Evaluation helps detect such issues, learners practice reviewing outputs for imbalance. They learn that bias is not always obvious and may appear subtly across many responses.
By identifying these patterns early, or retrain models to reduce risk.
Reliability Checks Before Deployment
Reliability means the model behaves predictably in real use, a reliable model should not produce random when the input is clear.
Before deployment, teams run test scenarios that reflect real usage, these include repeated queries, and unexpected user behavior. Learners understand that reliability testing protects both users and organizations.
They also learn that deployment is not the final step, where models must be monitored continuously to ensure they remain stable.
Human Review and Feedback
Automated metrics are beneficial, but when it comes to human review, it always stays relevant. Here people can judge tone, and usefulness better than automated tools.
Training programs encourage peer reviews, where learners compare outputs, and suggest improvements. This builds critical thinking and helps them understand evaluation beyond numbers.
Human feedback is especially important for content used in education, and customer communication.
Real World Use Cases
In real environments, generative AI is used in many ways. In customer support, it drafts responses. In marketing, it creates content ideas. In software development, it assists with code generation.
Each use case requires different evaluation standards, for example a creative task allows more variation. While a technical task requires strict accuracy where you will get exposure to see how evaluation adapts.
Conclusion
Evaluating generative AI is crucial as building it, and quality metrics help measure usefulness with Behavior analysis shows how the model reacts. Additionally, reliability checks ensure the system is safe. . With structured learning and hands on practice, learners gain the ability to judge AI systems. They learn that strong evaluation leads to responsible deployment and long term success. As generative AI continues to grow, professionals who understand how to evaluate models will always be valuable.

 Everywhere
Everywhere Members
Members Albums
Albums

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}